

Ensuring that AI assistants are Helpful, Honest, and Harmless (HHH) has become a standard goal in language model alignment. These three principles, popularized by OpenAI and others, serve as a north star for “good” AI behavior: a system should effectively help the user, be truthful in what it says, and avoid causing harm (e.g. through offensive or dangerous outputs). In practice, however, applying HHH is not straightforward — real-world scenarios often force trade-offs between these principles. Recent research argues that we need an adaptive interpretation of HHH, meaning the AI’s priorities among being helpful, honest, or harmless might need to shift depending on the context and task at hand. In this article, we explore what adaptive HHH alignment means, why it’s important, and how it could be implemented in AI systems.
The HHH Principles and Their Challenges
Defining HHH: At its core, helpfulness means the AI should aid the user in achieving their goals and provide relevant information or action. Honesty means the AI should tell the truth as much as possible and acknowledge uncertainties or limitations in its knowledge. Harmlessness means the AI should not produce content that is offensive, dangerous, or biased, and generally should not enable harmful outcomes These were originally outlined as a way to ensure AI systems act in line with human ethical values and safety expectations.
However, a rigid application of HHH can lead to problems. The principles can conflict with each other in certain situations. For example, what if being completely honest (truthful) might actually be harmful? Imagine an AI interacting with a distressed individual — a brutally honest answer about a medical prognosis might be truthful but could cause unnecessary harm or panic. Conversely, being harmless (avoiding a painful truth) might conflict with honesty. Even helpfulness can conflict with honesty: an AI might be able to help the user achieve an objective by being a bit deceptive or withholding information (think of a surprise party scenario, or a gamified learning environment where immediate answers spoil the learning process). Additionally, “helpfulness” itself is context-dependent — what’s helpful in one case might be unhelpful in another.
There are also ambiguities within each principle. What exactly counts as “harmless” content can depend on cultural context and personal sensitivities. Where’s the boundary between a harmless joke and a harmful insult? Definitions of honesty can vary: one researcher introduced the distinction between epistemic honesty (being upfront about the limits of one’s knowledge and not hallucinating facts) and interactive honesty (not misleading the user in the conversation context). An AI might truthfully say “I don’t have that information” (epistemically honest), which is good, but if the user specifically expected the assistant to find the info somewhere, they might see that as not very helpful. We can see how nuanced this gets.
Because of these challenges, a one-size-fits-all approach to alignment (where the AI always applies HHH the same way) is insufficient. This motivates the idea of making alignment adaptive to the situation
Why Alignment Must Adapt to Context
The core argument for adaptive HHH alignment is that different scenarios demand different priority trade-offs among being helpful, honest, and harmless. A recent position paper by Huang et al. (2025) emphasizes that real-world AI deployments face widely varying requirements and risks, so the AI’s behavior should be tuned accordingly. For instance:
- In a medical or legal setting, honesty (accuracy) should arguably take precedence above all. An AI giving medical advice must not fabricate facts or give false hope; being truthful is part of being helpful in this context. Harmlessness is also important (it should be sensitive in delivery), but if there’s a tension, honesty might be considered non-negotiable. The paper indeed notes that in healthcare, honesty is paramount.
- In an educational setting with minors, harmlessness might take the highest priority. An educational tutor AI should be very careful to avoid showing kids inappropriate content or harmful information. It might even sacrifice a bit of directness or completeness (honesty) if, say, simplifying an answer or omitting a harsh truth is better for the student’s well-being or learning stage. The research gives the example that in education, harmlessness may be prioritized to protect students.
- In open-ended casual conversations, helpfulness might be weighted more — the AI can be creative and engaging (helpful in an entertainment or companionship sense), as long as it stays generally honest and harmless. Here the exact balance might depend on user preferences; some users might tolerate more humor (even if slightly facetious) as long as it’s harmless, whereas others might prefer strict factual accuracy.
- In high-stakes security scenarios, harmlessness and helpfulness must be carefully balanced. Consider an AI assisting with cybersecurity: it should help the user by providing useful information to secure systems (helpfulness), but it must not inadvertently give tips that could be used maliciously or provide too much detail to the wrong user (harmlessness). In such a scenario, the AI might refuse certain “help” that conflicts with a broader harm-prevention goal. The paper mentions that in scenarios like cybersecurity, preventing misuse (harmlessness) while still being useful is a key trade-off
The upshot is that context matters tremendously. A static alignment that treats a casual chat the same as a clinical consultation could fail in one or both settings. What researchers propose is to make the AI’s interpretation of H-H-H conditional on context: before responding, the AI (or the system governing it) should consider, “What is the setting? What are the user’s needs and the risks here? Which principle is most critical right now?”
To enable this, Huang et al. introduce the concept of a “priority order” among HHH principles. Rather than saying “the assistant must always be simultaneously helpful, honest, and harmless,” we might specify an order of precedence that depends on the scenario. For example, Honesty > Harmlessness > Helpfulness might be the order for medical advice: first be truthful, then ensure no harm, then within those constraints be as helpful as possible. In another case, we might say Harmlessness > Helpfulness > Honesty, meaning it’s better to be safe and somewhat useful even if that means not telling the whole truth. The priority order provides a structured way to resolve conflicts: if an AI response could be super helpful but slightly violate harmlessness, in a context where harmlessness is top priority, the AI should refrain or adjust the answer.
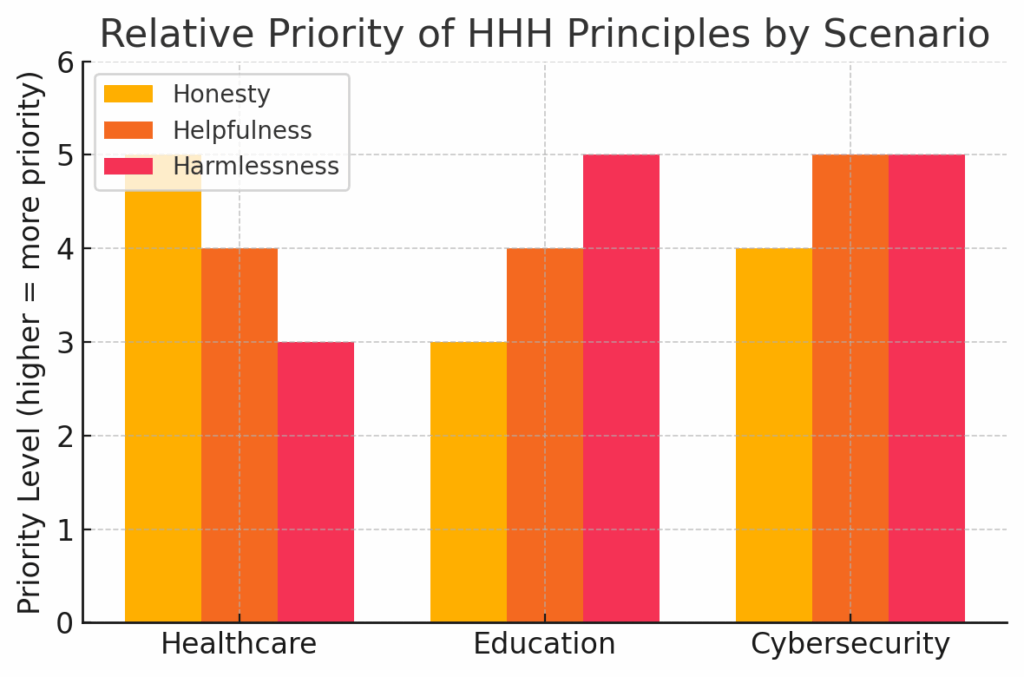
The figure above visualizes this concept: each domain has a different “profile” of HHH importance. This adaptive approach acknowledges that ethical AI is not one-size-fits-all. Humans do this kind of adaptation all the time (we communicate differently as a supportive friend, vs. as a doctor, vs. as a teacher), and aligned AI should do the same.
A Framework for Adaptive Alignment
To put adaptivity into practice, researchers propose a reference framework that an AI (or its designers) can use to adjust HHH principles to the context. The framework by Huang et al. suggests several key components:
- Contextual Definition of the Scenario: Clearly define the context in which the AI is operating. This includes identifying the user group or domain (e.g., “this is a medical diagnosis query from a non-expert patient”), the task type, and the goals. Context might also include the relevant stakes — is this a high-risk decision or a low-stakes chat? The AI (or developers during design) essentially asks: “Where am I, and what am I doing right now?”
- Value Prioritization (Value Anchoring and Scaling): Establish which of the HHH values should anchor the AI’s behavior in this context and to what degree. In other words, set a priority order or relative weighting for Helpful vs Honest vs Harmless. For example, anchor on safety (harmlessness) when in doubt for a given application, or decide that “honesty is the primary anchor for this domain, but we allow slight compromises on helpfulness,” etc. This step might involve policy guidelines or parameters that scale the importance of each principle.
- Risk Assessment: Evaluate the potential risks in the context and the tolerance for those risks. If you prioritize one principle over another, what could go wrong? For instance, if we let helpfulness dominate, is there a risk of the AI giving dangerous advice to be “helpful”? Conversely, if we are too strict on harmlessness, do we risk the AI being useless by refusing too many queries? A structured risk assessment helps ensure the chosen priority order won’t cause unintended consequences.
- Benchmarking and Metrics: Develop clear benchmark tests or metrics to measure how well the AI is doing on each of the HHH dimensions under the new interpretation For example, create scenario-specific evaluations: measure harmlessness in an education context by checking for any inappropriate content in outputs; measure helpfulness in that context by user satisfaction scores on answered questions; measure honesty by factual accuracy checks. These benchmarks let us objectively tune and verify the AI’s alignment in the intended way. In practice, this could involve multi-objective evaluation where an output is scored for truthfulness, usefulness, and safety. Having such data means one can iterate on the AI’s behavior.
- Transparency and Governance: Maintain transparency about how the AI decides on its responses and have governance in place. If an AI is adapting its alignment, both developers and users should ideally know the governing rules or have some insight. For instance, the system might log when it chooses to withhold information for safety reasons, or it might provide the user a brief note like “[Note: Some content was omitted for safety].” Governance also means oversight processes — e.g., human review for certain outputs, or audits to ensure the adaptive system isn’t drifting into undesired behavior. Essentially, keep a human-in-the-loop or at least informed about the AI’s alignment decisions.
These steps form a cycle that can be repeated for different contexts. They provide a structured approach to implement adaptive HHH so that it’s not arbitrary. The aim is to remain ethically grounded (we don’t throw HHH out the window; we tune it thoughtfully) while also being operationally effective (the AI stays useful and safe for each use case).
Concretely, an adaptive system might work like this: when a query comes in, the AI (or a governing policy layer) first classifies the context of the query. Then, based on that context classification, it activates a certain alignment profile (priority order). This could be seen as analogous to an AI having “modes” or policies: a medical advice mode, an open-chat mode, a kiddie mode, etc., each with different internal settings for how it balances helpfulness, honesty, and harmlessness.
Emerging Techniques and Research
Adapting alignment dynamically is an active area of research, and some technical approaches are being explored to achieve it. One interesting direction is the use of modular or Mixture-of-Experts models for alignment. Just as MoE architecture can improve raw performance (as in Qwen3-Next), it can also be used to balance multiple objectives like H, H, and H.
A recent paper titled “Too Helpful, Too Harmless, Too Honest or Just Right?” introduced a framework called TrinityX for alignment. TrinityX explicitly uses separately trained expert modules for each of the H, H, H dimensions. In their approach, you might have one sub-model that’s very good at being helpful, another specialized in being safe/harmless, and another focused on truthfulness. When a query comes in, TrinityX employs a calibrated routing mechanism to decide how to mix the outputs of these experts adaptively. Essentially, it’s like consulting three advisors (one prioritizing each principle) and then intelligently combining their advice into a final answer.
The routing is task-adaptive, meaning it doesn’t always give equal weight to each expert — it learns to calibrate the importance of helpfulness vs harmlessness vs honesty for the given input. For example, on a question where factual accuracy is critical, it might lean more on the “honesty” expert’s output; on a question that veers into potentially unsafe territory, it will put more weight on the “harmlessness” expert’s cautions. This is a neural network approach to implementing priority order internally.
Results from TrinityX are promising: it outperformed strong baseline models on dedicated benchmarks for each of the HHH aspects (such as Alpaca for helpfulness, BeaverTails for harmlessness, and TruthfulQA for honesty). Specifically, it achieved about +32% higher win rate in helpfulness, +34% better safety scores, and +28% more truthful answers relative to previous methods. Impressively, it managed to improve alignment without adding excessive overhead — in fact, due to the MoE design, TrinityX reduced memory usage and inference latency by over 40% compared to prior approaches that tried to do all-in-one alignment. This is a big deal: it suggests we can get better alignment and more efficiency at the same time by smartly modularizing the problem.
This kind of architecture is still in research, but it shows the feasibility of building alignment adaptivity into the model itself. There are also other approaches, such as Constitutional AI by Anthropic, which involves having a set of principles (a “constitution”) that the AI uses to self-criticize and refine its responses. One can imagine an adaptive constitutional AI that picks which principles apply based on context or even has different constitutions for different domains.
Another important aspect is tooling for evaluation. To trust an adaptive system, we need robust metrics — for example, to ensure that when it toggles into a mode that relaxes honesty a bit, it doesn’t start spouting complete falsehoods. Work is being done on HHH evaluation metrics and on detecting when models “fake” alignment (pretend to follow HHH but actually don’t). Continuous monitoring and analysis are key. This is where having strong data analysis in the deployment pipeline is useful: one can log interactions and use analytic tools like Pandas and Cana.
In summary, adaptive HHH alignment represents a maturation in how we align AI with human values: it’s not about finding one perfect balance, but about developing AI that can navigate the trade-offs intelligently depending on where it finds itself. This makes our AI not just a fixed rule follower, but a more contextually savvy assistant that acts appropriately in each situation — arguably a step closer to how a thoughtful human would behave.
Leave a Reply