

Qwen3-Next-80B is a recently unveiled 80-billion-parameter large language model that achieves high performance through an innovative sparse architecture. Developed as part of Alibaba’s Qwen series, Qwen3-Next-80B stands out by activating only a small fraction of its parameters for each token generation — dramatically reducing computation while preserving capability. In practical terms, it matches or even exceeds the performance of much larger models at a fraction of the training cost, and it can handle extraordinarily long contexts. Below, we break down what makes Qwen3-Next-80B notable, how it performs, and what it means for developers.
Architectural Innovations
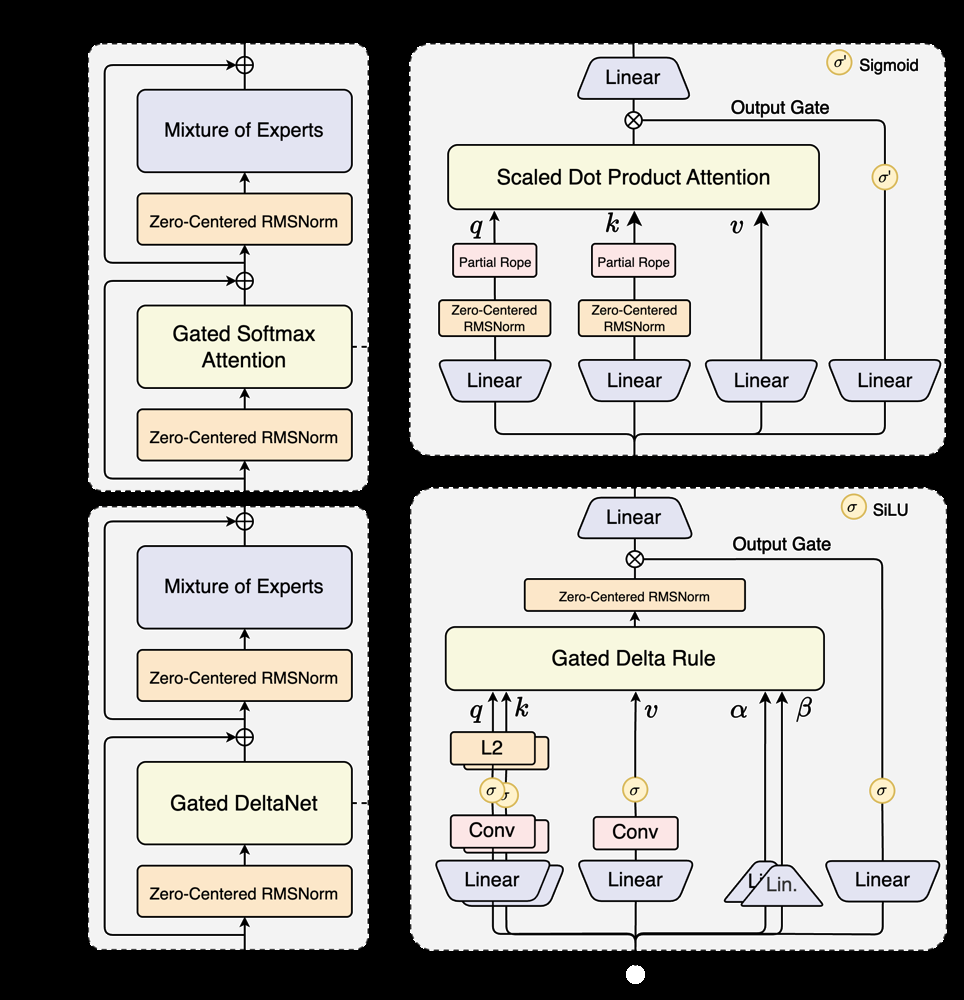
Hybrid Attention Mechanism: Instead of standard self-attention layers, Qwen3-Next-80B introduces a hybrid of Gated DeltaNet and Gated Attention layers. This design boosts the model’s ability to handle ultra-long sequences efficiently. Essentially, part of the model uses a novel linear attention (DeltaNet) to manage very long context without blowing up computation, while another part uses regular scaled dot-product attention gated in a way to focus on the most relevant information. The result is strong in-context learning performance even with input lengths in the hundreds of thousands of tokens.
High-Sparsity Mixture-of-Experts (MoE): Qwen3-Next-80B adopts an extreme Mixture-of-Experts architecture where only 3.7% of its parameters (about 3B out of 80B) are active for any given token generation. In practice, the model contains many expert sub-models (512 experts in total) but routes each query to only a small subset of 10 experts. This means the model taps into the “brains” of a few specialists rather than firing on all cylinders for every single prompt. The gating mechanism decides which experts are relevant for the prompt at hand. This approach dramatically reduces the floating-point operations per token and inference latency, while retaining the breadth of knowledge an 80B model can hold. It’s essentially the power of a massive model delivered with the efficiency of a much smaller one.
Multi-Token Prediction (MTP): Another innovation in Qwen3-Next is multi-token prediction, where the model can generate multiple tokens per inference step. By predicting chunks of text instead of one token at a time, the model speeds up text generation without sacrificing accuracy. This contributes to faster inference overall, complementing the MoE in keeping latency low even for long outputs.
Stability Optimizations: Training enormous models often runs into stability issues (divergence, overflow, etc.). Qwen3-Next includes training tweaks like zero-centered, weight-decayed LayerNorm and other techniques to stabilize both pre-training and fine-tuning. These optimizations help the 80B model train on its vast 15 trillion token corpus smoothly, and ensure it remains robust during use (avoiding weird glitches or sudden failures even when prompted with very long or complex inputs).
Performance and Efficiency Gains
Despite its sparse operation, Qwen3-Next-80B delivers performance on par with dense models that are much larger. In fact, Alibaba reports that the instruction-tuned version of Qwen3-Next-80B performs as well as their flagship 235B-parameter model on many benchmarks.
Crucially, it achieves this with far less computing cost. Training Qwen3-Next-80B required <10% of the GPU hours needed to train the older 32B dense model to reach similar results. And at inference time, it’s a speed demon for long inputs: when handling contexts beyond 32,000 tokens (far beyond the length of most LLMs), Qwen3-Next-80B processes text with over 10× higher throughput than the 32B model. In practical terms, it can chew through long documents or chats much faster.
One of the headline features is the model’s extended context window. Qwen3-Next-80B natively supports a 256K-token context (roughly equivalent to 200,000 words of text!) and can even be extended up to 1 million tokens with some modifications. This is an extraordinarily large context size — by comparison, many popular models struggle with 4K or 8K tokens, and even specialized long-context models usually max out at 32K or 100K tokens. With Qwen3-Next, you could feed entire books or multi-hour conversation histories into the model and it can still reason using all that context. The hybrid attention mechanism is what makes this feasible; it scales nearly linearly with sequence length, avoiding the quadratic slowdown that normally comes with very long inputs.
Another practical aspect is that Qwen3-Next-80B is open-source and released under an Apache-2.0 license. The model (including both the base and instruction-tuned versions, as well as a “Thinking” variant specialized for step-by-step reasoning) is available to download and use freely. Alibaba has made it accessible via Hugging Face, Kaggle, and their own ModelScope platform. This means developers can experiment with Qwen3-Next without hefty licensing fees, and even integrate it into their applications or fine-tune it for specific domains.
Outlook
Qwen3-Next-80B demonstrates a clear trend in AI: smarter architecture can beat brute-force size. For developers and organizations, this means access to top-tier language model capabilities is becoming more attainable, even without the vast infrastructure that the largest models demand.
We can expect future models to build on these ideas — perhaps increasing the number of experts, refining how the gating works, or further improving long-context handling. The fact that Qwen3-Next is open and accessible also means the community can explore novel applications for ultra-long context (imagine question-answering across entire libraries of documents, done by a single model in one go).
Leave a Reply