
One of the big challenges in training AI language models is the need for high-quality supervision — in other words, showing the model what the “right” answers look like. Traditionally, this is done with large datasets of human-written answers or by having humans provide feedback on the AI’s outputs (as in Reinforcement Learning from Human Feedback, RLHF). But what if there’s no clear right answer or no labeled data for a task? Recently, researchers from Meta AI unveiled an approach called “Compute as Teacher” (CaT) that tackles this problem by effectively letting the model teach itself using extra computation instead of external labels.
In simple terms, Compute as Teacher turns the model’s own inference-time computations into a source of learning signals. Rather than relying on an external answer key or human feedback for every query, the model uses additional computing power to generate multiple candidate answers and then synthesizes a “consensus” or “reference” answer from them. This reference becomes a pseudo-ground-truth that the model can then train against. In essence, the model is using its own reasoning process (using a lot of compute) to create new training data for itself, hence the phrase “compute as teacher”.
Let’s break down how this works and why it’s exciting for developers and researchers.
The Supervision Paradox: No Single Right Answer
The motivation for Compute as Teacher starts with what we might call the supervision paradox, that was covered in deep in this post by ArXiv In-depth Analysis. The most useful AI applications often involve problems that don’t have a single correct answer or any answer at all known in advance.
For example, if we want an AI to be a creative writer or give nuanced advice on personal matters, there is no ground truth dataset of perfect answers for those questions — even experts might disagree on what the “best” answer is. Creating a high-quality training dataset for such tasks is nearly impossible, or at least very expensive and slow (requiring expert human annotators). This is a bottleneck: we have big models that could do amazing things if taught properly, but we lack the labeled data to supervise them in those complex tasks.
Moreover, for many tasks, the notion of correctness is tricky. In open-ended dialogue, there isn’t a binary right/wrong; there’s a spectrum of quality, style, and usefulness. Traditional supervised fine-tuning forces the model to imitate the given answers, which might limit creativity or diversity. Reinforcement learning with a reward model helps, but training a good reward model itself often requires human-labeled comparisons.
This is where Compute as Teacher (CaT) comes in: it proposes to use the model’s own inference-time compute (i.e., making the model think harder by generating multiple answers internally) to serve as an alternative to reference answers. Instead of collecting an answer from a human, we make the model produce many possible answers and then derive a teaching signal from those. In effect, the model is exploring the solution space and then learning from its exploration.
How “Compute as Teacher” Works
The CaT approach, introduced in a 2025 paper by Jayalath et al., consists of a few key steps. Here’s a rundown in a more concrete way:
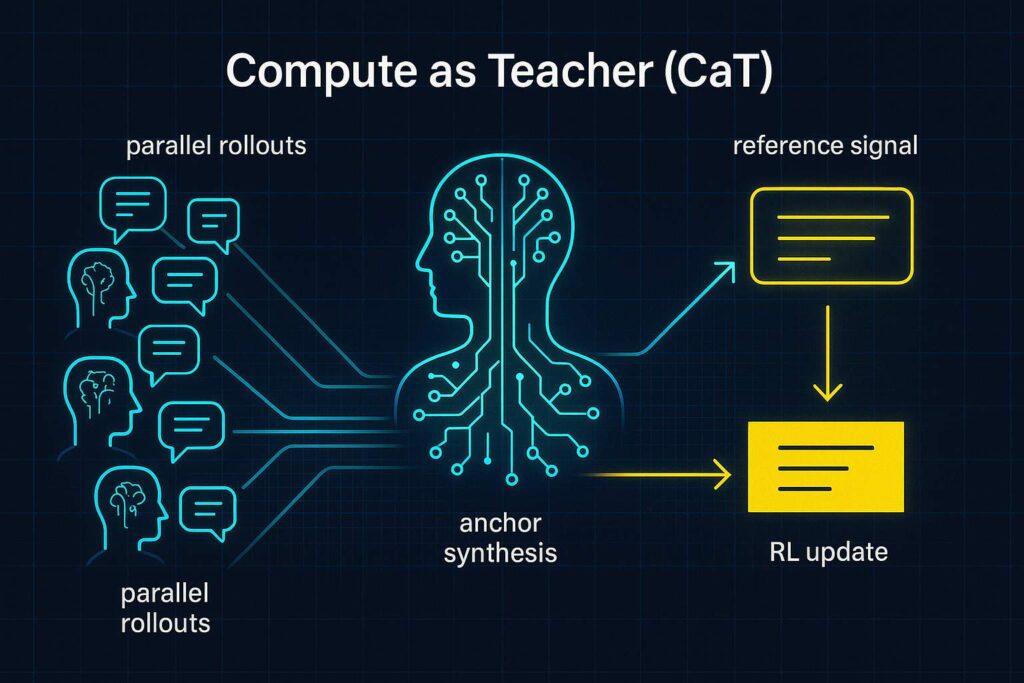
- Parallel Rollouts: When given a prompt or question, the model (let’s call the current version of the model π_t) is asked to generate not just one, but multiple outputs or answers in parallel. For example, suppose the user asks a question — the model will produce, say, 10 different responses (by sampling different continuations or using different randomness each time).
- Anchor Model & Synthesis of Reference: Alongside the current model, there is a frozen anchor model (π_0) — essentially an older snapshot of the model or a separate baseline model that remains unchanged. This anchor model takes all the multiple outputs from the current model and tries to synthesize a single better answer from them. Think of it as the anchor model doing an ensemble vote or writing a summary: it looks at the 10 candidates, and then it produces a new answer that reconciles them — it might take the best parts of each, fix contradictions, and fill in gaps. This synthesized answer is not simply choosing one of the outputs; it’s generating a potentially new answer that could be better than any individual attempt. The anchor acts like a teacher consolidating students’ ideas into a refined solution.
- Importantly, the anchor’s synthesis is done in a way that it doesn’t just copy one of the outputs wholesale. For verifiable tasks (like a math problem), the anchor might run a program or check each output and then produce the correct solution if any output got it right, or combine partial solutions. For open-ended tasks, the anchor is prompted to merge the outputs into one coherent answer. The anchor does not get to directly see the original question in the synthesis step (to avoid it just solving it independently); it only sees the model’s outputs. This forces the anchor to truly use those outputs as the basis.
- Reference-Free Reward Signal: Now we have a synthesized reference answer (let’s call it s). The beauty is that s was generated without any human or external reference — it came from the model’s own computations. Next, we use to compute rewards or learning signals for the original outputs. There are two regimes:
- Verifiable Tasks: If the task has an objective way to check answers (like math, where you can verify if an equation is solved correctly, or code where tests can be run), then the reference s can be used as a gold answer. For each original rollout answer o_i, we can compare it to s — e.g., did o_i reach the same final solution as s? If yes, that rollout is given a reward of 1, if not, 0. Essentially, we treat s as the ground truth and reward the model for matching it. If s is a correct solution to the problem (which, hopefully, it is, especially if at least one of the attempts had the correct answer), this pushes the model to learn that solution.
- Non-Verifiable (Open-ended) Tasks: If there’s no straightforward way to auto-check correctness (like an opinion answer or a piece of creative writing), CaT creates a rubric from the synthesized answer. The anchor model can generate a set of criteria or questions (a rubric) that a good answer should satisfy, based on s. Then, an independent judge model (another language model, possibly a simpler one or an earlier version, not the same as the anchor) will evaluate each original output o_i against these criteria. For example, if s is a synthesized ideal answer, the rubric might be a list of requirements like “mentions X, explains Y, uses a polite tone, etc.” The judge checks each o_i: did it mention X? did it explain Y? etc., and gives a score (say it satisfied 3 out of 5 criteria, so score = 0.6). That score becomes the reward for that output. This way, even for open-ended tasks, we derive a supervisory signal from s without needing a human to grade the answers.
- Learning (Updating the Model): The final step is to use these rewards to update the model π_t so that it produces better outputs next time. This can be done with a reinforcement learning algorithm. The paper uses a variant of Proximal Policy Optimization adapted for multiple outputs, called GRPO (Group Regularized Policy Optimization). Essentially, the model gets nudged to make the kind of output that would match the synthesized reference. Over time, the model should improve because it’s learning from its own exploratory attempts. Notably, the authors found that after doing this training (which we might call CaT-RL), the model can surpass the quality of the initial synthesized teacher signal. That means the student (the updated model) eventually becomes better than the teacher (the anchor reference), which is the goal of any teaching process.
Why It’s Powerful: No Labels Needed, and Better Than Best-of-N
This approach might sound somewhat similar to doing a “best of N” selection (where you just pick the best output out of a bunch). But it’s more powerful than that. In a best-of-N scheme, if none of the N outputs is good, you’re out of luck. Compute-as-Teacher instead can produce a new answer that is better than all of them by combining information. For instance, imagine a math problem where none of the 10 tries fully solved it, but different tries got different pieces of the problem right. One attempt may have done a correct first step, another attempt got the second step, etc. The synthesized answer could piece together the correct steps from each attempt to form a fully correct solution, even though each individual rollout was wrong. This synthesized answer can still be used as a teaching signal, effectively allowing the model to learn the correct solution from a set of wrong attempts by leveraging their partial correctness. Traditional best-of-N would have just thrown all attempts out as failures in that case, whereas CaT salvages them to create a potentially correct answer.
The researchers noted that performance improves with the number of rollouts G— the more parallel attempts the model can draw from, the more likely the anchor can synthesize a high-quality answer by correcting errors and filling gaps. This is especially true in tasks like math where eventually one attempt might hit the correct solution or collectively they have all the pieces. There is a trade-off though: more rollouts means more compute used at inference time. They found that beyond a certain number of parallel tries, returns diminish for open-ended tasks (lots of similar attempts don’t add new info). But the approach is nicely scalable: if you have compute to spare, using 100 rollouts will likely give an even better synthesized answer than using 10.
The Results
So, does this self-teaching actually make the model better? The researchers tested CaT in two ways: as a pure inference-time method (where the model doesn’t permanently learn, but just uses the technique on the fly to answer a question better), and as a training method (CaT-RL) where the model’s parameters are updated so it improves long-term.
The experiments were done on some smaller-scale models (to keep it tractable): they used a 4B-parameter model (“Gemma 3” 4B), another called Qwen 3 (4B), and Llama 3.1 (8B) for various tasks. The tasks included MATH-500 (a set of math problems) and HealthBench (medical Q&A) as representative verifiable and non-verifiable domains.
Inference-time improvement: Without any additional training, just using CaT to answer questions, they saw substantial boosts in performance. On the MATH-500 dataset, using CaT (with multiple rollouts and synthesis) gave up to a +27% improvement in accuracy over the model’s normal single-shot performance. On HealthBench, which is more open-ended, it gave about a +12% improvement in whatever metric they used (likely some form of accuracy or usefulness score). These gains are purely from letting the model do extra thinking and then choosing a synthesized answer — no human in the loop, no new training. This suggests that many errors the model would normally make can be fixed by simply allowing it to reconsider and combine answers, akin to a student checking their work with multiple approaches.
Post-training improvement (CaT-RL): When they actually used the synthesized references as a training signal to fine-tune the model (reinforcement learning loop), the model improved even further. They report up to +33% improvement on MATH-500 and +30% on HealthBench after training the model with CaT signals, compared to the original model. In other words, after this self-generated practice, the model got significantly better at these tasks permanently. Impressively, the fine-tuned model ended up surpassing the quality of the initial synthesized answers, meaning it wasn’t just memorizing those — it generalized and became a stronger problem-solver.
The chart below illustrates the relative performance gains observed:
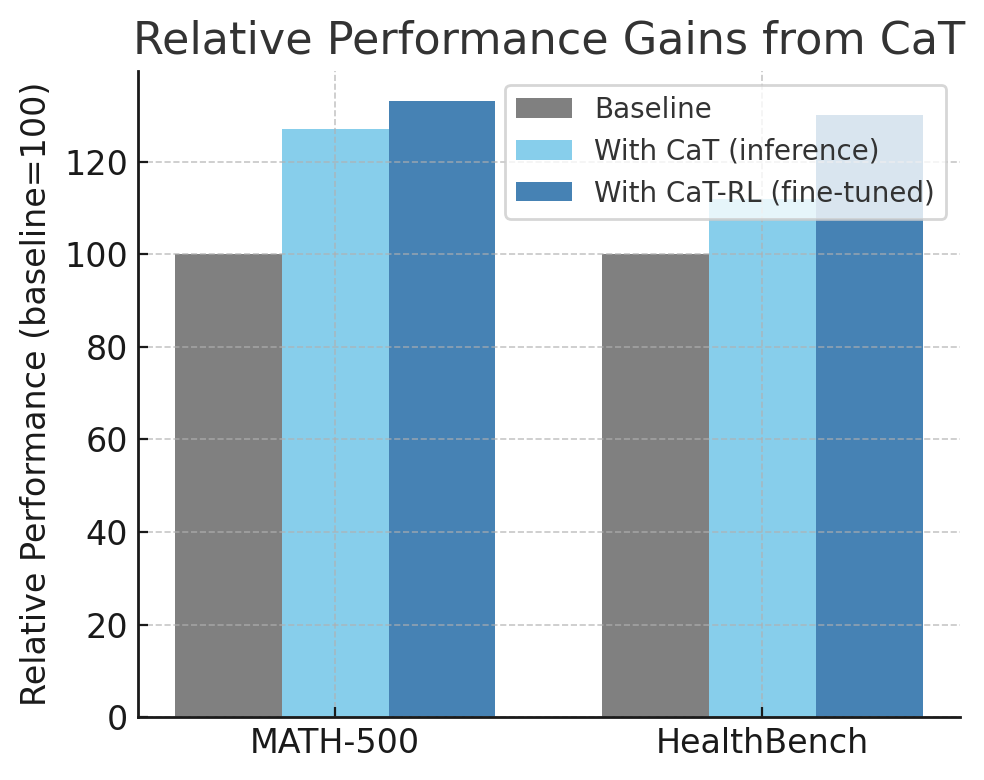
As the figure suggests, turning up the “compute” and letting the model iterate can be almost as useful as turning up the “data” in some cases. This approach is essentially trading more computation to reduce the need for direct supervision. Instead of paying humans to label or craft an answer, you pay for more CPU/GPU cycles, and you get a teaching signal out of it.
Implications: Real-Time Adaptation
- Less Reliance on Labeled Data: It shows a pathway to improve models even when labeled examples or explicit feedback are scarce or nonexistent.
- On-the-Fly Adaptation: Since CaT can be applied at inference time without changing the model weights, one could imagine AI systems that adapt on the fly for difficult queries by allocating more compute.
- Compute vs. Data Trade-off: CaT highlights an interesting trade: with enough compute, a model can generate its own surrogate data (in the form of these synthesized answers and rubrics) to learn from. This points to a future where we might spend as much effort on clever inference algorithms as on training algorithms.
In conclusion, “Compute as Teacher” is a clever solution to the problem of learning without ground truth. By making the model its own teacher — using additional computation to generate references — it opens a pathway for self-improvement that doesn’t rely on constant human feedback. It’s a great example of trading resources: if labeled data or human time is scarce, use more machine time to compensate. For AI practitioners, it suggests new strategies for refining models: if you can’t get good labels, maybe have the model engage in a structured debate with itself and learn from that. Indeed, having robust data analysis pipelines to inspect the results of such self-training will be important, for that the recomendation is to use something like Pandas or Cana.
Leave a Reply